Docs Diver
Docs Diver is an AI-powered document intelligence workspace that lets users upload PDFs, ask questions in natural language, and receive citation-grounded answers generated through semantic search and Retrieval-Augmented Generation (RAG).
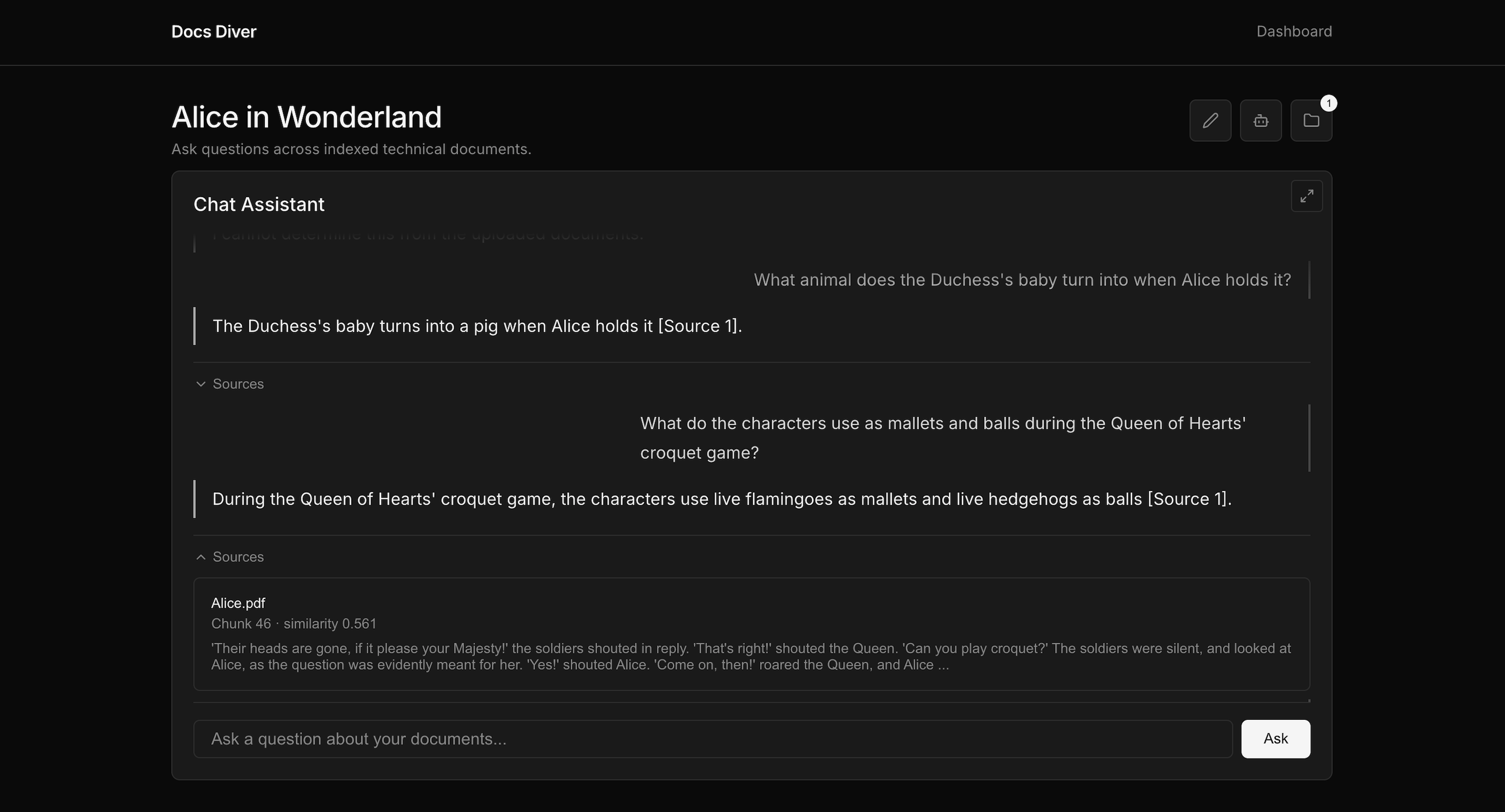
Docs Diver is a full-stack AI application built to explore the practical challenges of modern Retrieval-Augmented Generation (RAG) systems.
The platform allows users to upload PDF documents, automatically extract and structure their contents, generate vector embeddings, and store them in a PostgreSQL database using pgvector. Users can then query their documents through a conversational interface, receiving answers grounded in the source material rather than relying solely on the language model’s internal knowledge.
To improve retrieval quality, the application implements structure-aware document chunking, semantic similarity search, chunk filtering, and citation tracking. Retrieved sources can be inspected through a dedicated source preview interface, including PDF page previews and chunk-level context.
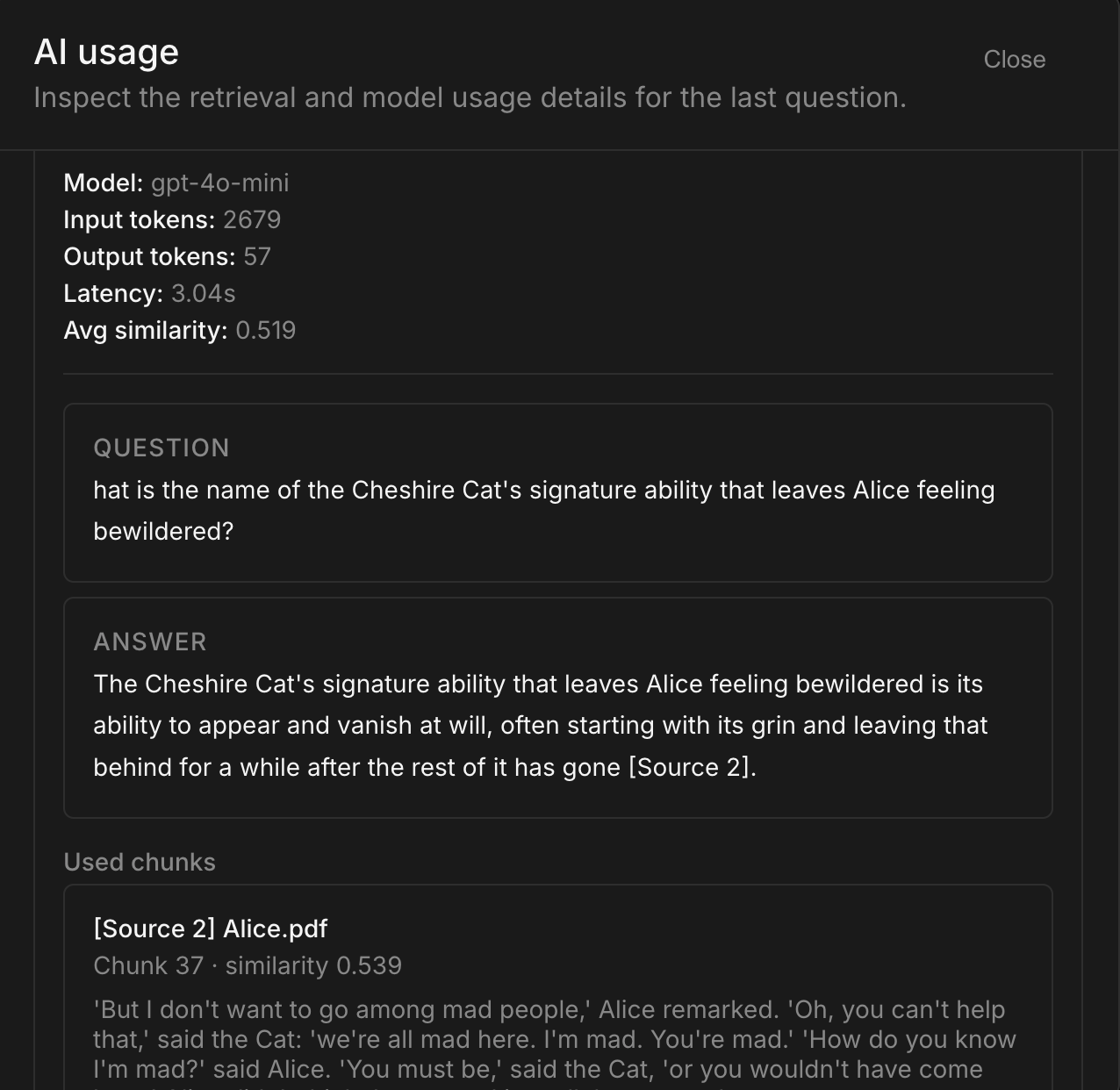
Beyond answering questions, Docs Diver focuses heavily on transparency and observability. The system records retrieval metadata, similarity scores, latency information, token usage estimates, and chunk-selection data, allowing developers to inspect and evaluate retrieval performance through a dedicated evaluation interface.
The project was built with Next.js, TypeScript, PostgreSQL, Prisma, pgvector, OpenAI APIs, the Vercel AI SDK, and React PDF, and serves as a practical exploration of AI product engineering, semantic search systems, and production-oriented LLM workflows.

Like what you see?
Let's discuss how I can help bring your next project to life with the same level of quality and attention to detail.